
1. 理解问题

我们需要明确什么是“重复字段”,在数据库中,如果某个字段(列)中的多个记录具有相同的值,那么这些记录就被视为该字段的重复值,在一个用户信息表中,如果有多个用户记录具有相同的电子邮件地址,则这些电子邮件地址就是重复的。
2. 基本查询结构
要查询某个字段的重复值,我们通常使用GROUP BY和HAVING子句,以下是基本查询的结构:
SELECT column_name, COUNT(column_name) FROM table_name GROUP BY column_name HAVING COUNT(column_name) > 1;
这里,column_name是你想要检查的字段名,table_name是你的表名,这个查询会返回每个值及其出现的次数,只包括那些出现次数大于1的值,即重复的值。
3. 示例
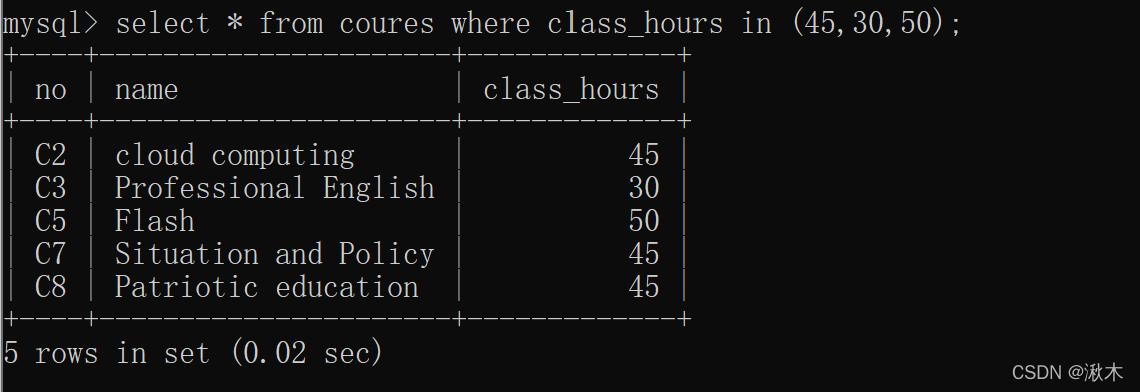
假设我们有一个名为users的表,其中有一个字段叫做email,我们要找出所有重复的电子邮件地址。
步骤1:选择字段和表名
我们的字段名是email,表名是users。
步骤2:应用查询结构
将字段名和表名填入基本查询结构中,得到如下查询:
SELECT email, COUNT(email) FROM users GROUP BY email HAVING COUNT(email) > 1;
步骤3:执行查询
执行上述查询后,你会得到一个结果集,列出了所有重复的电子邮件地址及其出现的次数。
4. 进阶技巧
在某些情况下,你可能想要获取更多关于重复记录的信息,比如它们的ID或其他字段的值,这时,你可以使用子查询或连接查询来实现。
使用子查询
SELECT *
FROM users
WHERE email IN (
SELECT email
FROM users
GROUP BY email
HAVING COUNT(email) > 1
);
这个查询会返回所有具有重复电子邮件地址的用户记录的完整信息。
使用连接查询
SELECT u1.*
FROM users u1
JOIN (
SELECT email
FROM users
GROUP BY email
HAVING COUNT(email) > 1
) u2 ON u1.email = u2.email;
这个查询与上面的子查询效果相同,但使用了连接操作。
5. 相关问题与解答
Q1: 如何删除重复的记录?
A1: 删除重复记录通常需要谨慎操作,因为可能会不小心删除重要的数据,一种常见的方法是先识别出重复的记录,然后根据某些条件(如时间戳或ID)决定保留哪些记录,最后删除其余的,这通常需要结合使用DELETE语句和适当的WHERE条件。
Q2: 如果我只想找出某个特定字段的唯一值怎么办?
A2: 如果你想找出某个字段的唯一值,可以使用类似的查询,但修改HAVING子句的条件为COUNT(column_name) = 1,这将返回只出现一次的字段值。
希望这篇文章能帮助你理解和掌握如何使用SQL查询来找出表中的重复字段值,通过这些方法,你可以有效地进行数据清洗和去重,确保数据库的准确性和一致性。
来源互联网整合,作者:小编,如若转载,请注明出处:https://www.aiboce.com/ask/14031.html