
基础用法

(图片来源网络,侵权删除)
假设我们有一个名为students的表,其中包含学生的信息,如下:
| id | name | age | city |
| 1 | alice | 20 | beijing |
| 2 | bob | 22 | shanghai |
| 3 | charlie | 23 | guangzhou |
| 4 | alice | 20 | beijing |
| 5 | david | 21 | hangzhou |
如果我们想要找出所有出现在表中的城市,而不关心每个城市出现的次数,我们可以使用distinct关键字来查询不重复的城市数据:
select distinct city from students;
这将返回以下结果:
| city |
| beijing |
| shanghai |
| guangzhou |
| hangzhou |
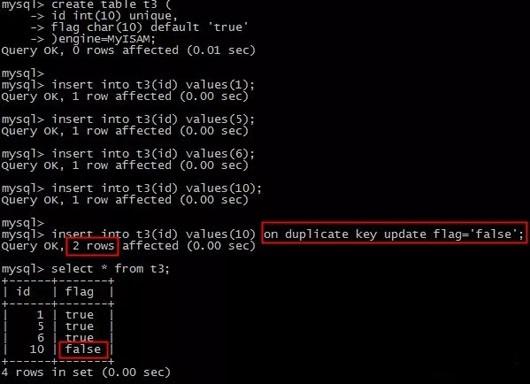
多列去重
如果需要基于多个列进行去重,可以在distinct后列出这些列,如果我们想查找表中不重复的姓名和年龄组合,可以使用以下查询:
select distinct name, age from students;
返回的结果将只包含唯一的name和age组合:
(图片来源网络,侵权删除)
| name | age |
| alice | 20 |
| bob | 22 |
| charlie | 23 |
| david | 21 |
注意,尽管alice出现了两次,但由于她的年龄相同,所以只被计算一次。
与聚合函数结合使用
我们需要对去重后的数据进行计数或其他统计操作,这时候可以将distinct与聚合函数如count()结合使用,要计算不同城市的学生数量,可以这样写:
select count(distinct city) from students;
这会返回不重复城市的数量。
相关问题与解答
q1: 如果我只想获取前几个不重复的数据怎么办?
a1: 你可以使用limit子句来限制结果集的大小,如果你只想获取前两个不重复的城市,你可以这样写:
select distinct city from students limit 2;
q2:distinct能否与其他排序命令一起使用?
a2: 是的,distinct可以与order by子句一起使用来对结果进行排序,如果你想按照城市名称的字母顺序对不重复的城市进行排序,你可以这样写:
select distinct city from students order by city;
这将返回一个按城市名称排序的唯一城市列表。
来源互联网整合,作者:小编,如若转载,请注明出处:https://www.aiboce.com/ask/20760.html